Minería de datos
Índice
1 Validación de datos.
1.1 Validación de sistemas de medida - ISO 5725
1.1.1 parte 1
- intro
- veracidad
- proximidad entre
- media aritmética de muchas medidas de prueba
- valor aceptado de referencia
- términos relacionados: exactitud, sesgo, error sistemático
- proximidad entre
- precisión
- factores que influyen sobre la precisión
- operario
- equipamiento
- calibración del equipamiento
- entorno (temperatura, humedad…)
- tiempo entre mediciones
- repetibilidad
- variación mientras dichos factores se mantienen constantes
- variación residual
- reproducibilidad
- variación mientras los factores varían
- repetibidad ≤ precisión ≤ reproducibilidad
- acuracidad (¿exactitud?) = veracidad + precisión
- veracidad
- definiciones
- valor observado
- resultado de la prueba
- nivel de la prueba = media de los resultados de las pruebas de todos los laboratorios para cierto espécimen
- celda = resultados de un nivel obtenidos por cierto laboratorio
- valor aceptado de referencia
- acuracidad
- veracidad
- sesgo
- sesgo de laboratorio = media del laboratorio - valor de referencia
- sesgo del método de medición
- componente laboratorial del sesgo = sesgo del laboratorio - sesgo del método
- precisión
- repetibilidad
- condiciones de repetibilidad
- mismo método
- probetas idénticas
- mismo laboratorio
- mismo operario
- mismo equipamiento
- en intervalos cortos de tiempo
- desviación típica de repetibilidad
- r = límite de repetibilidad = percentil 95 de |medida1 - medida2| en condiciones de repetibilidad
- reproducibilidad
- condiciones de reproducibilidad
- mismo método
- probetas idénticas
- laboratorios distintos
- operarios distintos
- equipamientos distintos
- desviación típica de reproducibilidad
- R = límite de reproducibilidad = percentil 95 de |medida1 - medida2| en condiciones de reproducibilidad
- atípico (outlier)
- experimento de evaluación colaborativo
- mismo método
- probetas idénticas
- se evalúan varios laboratorios
- implicaciones prácticas
- cortos intervalos de tiempo: no deben afectar a la independencia
- modelo estadístico
- y = m + B + e
- m es la media general (esperanza) = nivel de la prueba
- B es el componente laboratorial del sesgo bajo condiciones de repetibilidad
- e es el error aleatorio bajo condiciones de repetibilidad
- B es un efecto aleatorio
- B \(\hookrightarrow N\,(0;\sigma_L)\)
- var(B) = \(\sigma^2_L\)
- incluye varianza
- entre operarios
- entre equipamientos
- e es un efecto aleatorio
- var(e) = \(\sigma^2_W\) = varianza intra-laboratorio = varianza de repetibilidad = \(\sigma^2_r\)
- se supone igual en todos los laboratorios
- la varianza de reproducibilidad es \(\sigma^2_R = \sigma^2_L+\sigma^2_W\)
- y = m + B + e
- diseño experimental
- cálculo del número de laboratorios y de observaciones necesarios
- uso de los resultados
- publicar las desviaciones típicas \(\sigma_r\) y \(\sigma_R\)
{kind=link}
{kind=link}
1.1.2 parte 2
- análisis
- celda: combinación de laboratorio y nivel
- redundancia: si hay más de "n" datos, muestrear exactamente "n" de ellos
- ausentes:
- si hay 0 datos válidos, prescindir de la celda
- si hay 0 < m < n datos válidos, que los "m" sean tenidos encuenta por el algoritmo habitual
- atípicos: tratamiento similar a los ausentes (¿?)
- laboratorios atípicos: el experto en estadística decidirá si descartarlos
- datos erróneos: descartarlos o corregirlos
- hay equilibro/balance si
- laboratorios i = 1, …, p
- niveles j = 1, …, q
- réplicas en cada nivel k = 1, …, n
- total de n.p.q resultados \(y_{ijk}\) de la prueba
- formularios
- A: medidas \(y_{ijk}\) en una tabla
- B: medias por nivel: \(\bar y_{ij}\)
- C: cuasi desviaciones típicas por nivel: \(\bar y_{ij}\)
- consistencia
- entre laboratorios (\(h\) de Mandel) \[ h_{ij} = \frac {\bar y_{ij}-\bar{\bar y_j}} {\sqrt { \frac1{(p_j-1)} \sum_{i=1}^{p_j}(\bar y_{ij} - \bar{\bar y_j})^2 }} \]
- intra-laboratorio (\(k\) de Mandel) \[k_{ij} = \frac {s_{ij}\,\sqrt{p_j}} {\sqrt{\sum s_{ij}^2}} \]
- detectar laboratorios anómalos
- todos los signos de \(h\) son iguales para un laboratorio
- \(k\) demasiado alta (mala repetibilidad)
- \(k\) demasiado baja (redondeo excesivo)
- histogramas para detectar multimodalidad (dos poblaciones)
- umbrales
- p-valor > 0,05: se acepta como correcto
- p-valor < 0,05: rezagado (se indica mediante *)
- p-valor < 0,01: atípico (se indica mediante **)
- prueba de homoscedasticidad entre laboratorios
- C de Cocran \[C_j = \frac{S_j^2}{\displaystyle \sum_{i=1}^N S_i^2}\]
- en R:
GAD::C.test (lm (respuesta ~ factor)) - otras alternativas en Rcmdr (F, Levene, Bartlet…)
- eliminar laboratorios atípicos (con precaución): varianza demasiado alta
- prueba para uno o dos atípicos
- cálculo de componentes de varianza
1.2 Análisis de varianza R&R
- Reproducibilidad = Varianza total = Repetibilidad + Var. medida
- Var. medida = Var. aparato + Var. operario
- ¿Interacciones aparato × operario?
- Repetibilidad ≅ Var. intrínseca
- Reproducibilidad ≅ Var. total
- análisis de varianza con 2 factores aleatorios
- operario (A) con niveles i = 1, …, a
- probeta (B) con niveles j = 1, …, b
- cada combinación se repite n veces (k = 1, …, n)
- sumas de cuadrados
- SCT = \(\sum_{i,j,k} (x_{ijk} – \bar x)^2\)
- SCE = \(\sum_{i,j,k} (x_{ijk} – \bar x_{ij\cdot})^2\)
- SCA = b · n · ∑i (xi··-x)2
- SCB = a · n · ∑j (x·j·-x)2
- Interacción = SCI = SCT – SCE – SCA – SCB
- cuadrados medios
- CME = SCE : (a · b · (n – 1))
- CMA = SCA : (a – 1)
- CMB = SCB : (b – 1)
- CMI = SCI : [(a–1)·(b–1)]
- esperanzas (efectos aleatorios)
- E(CME) = \(\sigma^2\)
- E(CMA) = \(\sigma^2 + b·n·\sigma_A^2 + n·\sigma^2_I\)
- E(CMB) = \(\sigma^2 + a·n·\sigma_B^2 + n·\sigma^2_I\)
- E(CMI) = \(\sigma^2 + n·\sigma^2_I\)
- resultados
- Contraste de hipótesis
- interacción
- \(H_0: \sigma_I=0\)
- \(H_1: \sigma_I>0\)
- efecto
- \(H_0: \sigma_A=0\)
- \(H_1: \sigma_A>0\)
- Estimación de \(\sigma_A^2\)
- sin interacción: (CMA – CME) : (b·n)
- con interacción: (CMA – CMI) : (b·n)
- “Precisión” = 6·\(\sigma_A\)
- Razón P:T = 6·\(\sigma_A\) : (rango de tolerancia)
- Contraste de hipótesis
- en R
- efectos fijos
library ("nlme") # para Machines M <- as.data.farme (Machines) # para quitar la clase groupedData class (M$Worker) <- "factor" # para quitar la clase ordered # y evitar niveles Worker.L .Q .C ^4 ^5 lm (score ~ Worker + Machine, M) aov (score ~ Worker + Machine, M) ## con interacciones aov (score ~ Worker * Machine, M) aov (score ~ Worker + Machine + Worker:Machine, M) # equivalente lm (score ~ Worker * Machine, M)
- efectos aleatorios
library ("VCA") # para anovaVCA ó anovaMM anovaVCA (score ~ Machine * Worker, M) # componentes de varianza anovaVCA (score ~ Machine + Worker, M) # sin interacción anovaMM (score ~ Machine + (Worker), M) # modelo mixto Machine fijo, Worker aleatorio anovaMM (score ~ Machine * (Worker), M) # modelo mixto con interacción ## contraste de interacción library ("lme4") # para lmer lmer (score ~ (1|Machine)+(1|Worker)+(1|Machine:Worker), M) -> mabi lmer (score ~ (1|Machine)+(1|Worker), M) -> mab anova (mab, mabi) ## contraste de un efecto lmer (score ~ (1|Machine), M) -> ma anova (ma, mabi) ## con otro paquete (sólo para diseños equilibrados/balanceados) library (GAD) W = as.random (M$W) Ma = as.random (M$Machine) gad (lm (score ~ W * Ma, M))
- efectos fijos
- Si no hay gausianidad…
- Estimación – Bústrap (muestreo autosuficiente, bootstrapping). – La muestra se considera representativa de la población. – Iterar: muestreo con reposición y cálculo de estimador.
- Contraste de hipótesis – Permutas. – Barajar observaciones entre operarios y calcular estadígrafo del contraste.
- Identificación de valores erróneos
- Tipificación
- Cuantiles (diagramas de caja)
- Chauvenet
- Según distribución: gausiana, exponencial
- Atípicos multivariantes
- Mahalanobis
x = rnorm(1e4,5,1) y = x + rnorm(1e4,0.5,0.1) X = rbind(cbind(x,y),c(3,7)) plot(X) S = cov(X) M = sqrt (diag (X %*% solve(S) %*% t(X))) boxplot(M)
2 Series temporales.
Referencia básica: Introductory time series with R
2.1 Datos de ejemplo
@carleos2.epv.uniovi.es:/home/iot/dat
2.1.1 saldo de cuenta bancaria
- cuenta.rda
2.1.2 56 ms de señales eléctricas
- señales-eléctricas.*
- «medicion corriente.csv»
2.1.3 sensores de temperatura en ordenadores
- one
- dos temperaturas
- bellman
- una temperatura
- carleos2
- 4 temperaturas de 4 cores
- 1 temperatura de tarjeta gráfica
- carleos
- 1 temperatura ACPI zona termal
- 1 temperatura core
- labogen
- 1 temperatura Asus-ISA
- 2 temperaturas ACPI zona termal
- 1 temperatura package id 0
- 4 temperaturas core
- 1 temperatura Radeon
- zadeh
- tarjeta gráfica
- ¿
in0_input? - 1 temperatura
- ¿
- cores
- package id 0
- cores 0 1 2 3 4 8 9 10 11 12
- tarjeta gráfica
- presión arterial y pulso
- tensiones.rda
2.2 Operaciones básicas en R
2.2.1 clase «ts»
- usar objeto «ts»
?AirPassengers a <- AirPassengers a unclass (a) plot (a) start (a) end (a) frequency (a) plot (aggregate (a)) # totales anuales boxplot (a ~ cycle(a)) # medianas mensuales window (a, 1952, c(1953,12)) # datos de enero 1952 a diciembre 1953 window (a, c(1952,1), c(1953,12)) # idem window (a, c(1952,8), freq=TRUE) # datos de agosto
- generar objeto «ts»
load ("temperaturas_one.rda") # portátil Acer Aspire One ls () serie1 <- ts (temp1, freq=60) # periodo horario
EJERCICIO
- usar
temperaturas_zadeh.rda - crear serie temporal de «temp1.» con periodo horario, diario y semanal
2.2.2 biblioteca «xts»
install.packages ("xts") library (xts) ax <- as.xts (a) # AirPassengers as.xts (b$Saldo, b$Fecha.Valor) -> bx # cuenta bancaria ## si dejamos «medicamento», se trasforma todo en cadenas: tensionesx <- as.xts (tensiones[,-grep("fecha|medicamento",names(tensiones))], tensiones$fecha) plot (tensionesx) ## el índice de tiempo puede tener formatos varios class (index (ax)) as.Date (index (ax)) class (index (bx)) ## se pueden extraer intervalos temporales usando fechas ISO: AAAA-MM-DD HH:MM:SS ax["1953"] # un año ax["1953",] # idem ax["1953-10"] # octubre ax["/1953"] # hasta cierto año ax["1960-03/"] # desde cierto mes ax["1952-11/1953-03",] # entre fechas first (ax, "2 year") # primeros años last (ax, "3 month") # últimos meses ## periodos periodicity (ax) periodicity (bx) periodicity (tensionesx) ## extremos de los periodos endpoints (tensionesx, "week") endpoints (ax, "year") ## cambiar periodicidad to.period (ax, "year") plot (to.period (bx, "year")) plot (to.period (tensionesx, "week")) ## describir por periodo period.apply (tensionesx, endpoints(tensionesx,"month"), colMeans, na.rm=TRUE)
EJERCICIO
- Trasformar el dataframe
datosdetemperaturas_zadeh.rdaen un objetoxts. - Extrae los datos obtenidos hasta las 11h21 del 12 de diciembre de 2018.
- Obtén medias diarias, semanales y mensuales.
2.3 Descomposición: tendencia y estacionalidad.
2.3.1 notación
- serie \[\{x_t\mid t=1,\dots,n\}=\{x_1,\dots,x_n\}\]
- media \[\hat x = \frac{x_i}n \]
- predicción o pronóstico \[\hat x_{t+k\mid t}\]
- componentes
- \(m_t\) tendencia
- \(s_t\) estacionalidad
- \(z_t\) residuo
2.3.2 modelos
- aditivo \[x_t = m_t +s_t +z_t\]
- multiplicativo \[x_t = m_t \cdot s_t +z_t\]
2.3.3 estimación
- tendencia
- media móvil; p.ej. anual \[\hat m_t = \frac{\frac12 x_{t-6}+x_{t-5}+\dots+x_{t+5}+\frac12 x_{t+6}}{12}\]
- regresión local (loes)
- estacionalidad
- aditiva: \[\hat s_t = x_t - \hat m_t\]
- multiplicativa: \[\hat s_t = \frac{x_t}{\hat m_t}\]
plot (decompose (a)) # aditiva plot (stl (a, "periodic")) # idem mediante loes plot (decompose (a, type="mult")) # multiplicativa decompose # usa «filter» para media móvil identical (filter (a, c(1/2,rep(1,11),1/2)/12), decompose (a) $ trend) saldo <- decompose (ts (to.period(bx,"month")$bx.Close, start = c(2003,11), freq = 12)) plot (saldo) saldo$figure # efecto estacional (desde noviembre)
EJERCICIO
- Comenta la descomposición de la serie
temperaturas_onecon periodos de 60 (minutos). - Prueba a descomponer algunas series de
tensionesxsemanales a partir de máximos diarios. - Prueba a descomponer algunas series de
temperaturas_zadehcon periodos diarios o semanales.
2.4 Correlogramas.
- autocorrelación de orden \(k\) \[\rho_k=\mbox{cor}(x_t,x_{t+k})\]
- estimador de autocovarianza\[c_k=\frac1n\sum_{t=1}^{n-k}(x_t-\bar x)(x_{t+k}-\bar x) \]
- estimador de autocorrelación \[r_k=\hat \rho_k= \frac{c_k}{c_0}\]
acf (a) # correlograma: autocorrelación frente a retardo acf (a) $ acf # valores numéricos acf (a - decompose(a)$trend, na.action=na.pass) # quitando tendencia ## los residuos son la componente aleatoria tras quitar tendencia y estacionalidad (a-decompose(a)$trend-decompose(a)$seasonal) - decompose(a)$random acf (decompose(a)$random, na.action=na.pass) # se mantiene un efecto estacional notable sd (a) # desviación original = 119.9663 sd (a - decompose(a)$trend, na.rm = TRUE) # desviación sin tendencia = 41.11491 sd (decompose(a)$random, na.rm = TRUE) # desviación residual 19.34053 ## «decompose» usa «filter»; «stl» usa regresión local (como «lowess» y «loess») stl (a) plot (stl (a))
- si \(\rho_k=0\) entonces \(r_k\) es aproximadamente gausiana con media \(-\frac1n\) y varianza \(\frac1n\)
- líneas discontinuas del correlograma = \(-\frac1n\pm\frac2{\sqrt n}\)
- cruzcorrelograma: para varias series
tendias <- do.call (cbind, lapply (1:6, function(i) to.period (tensionesx[,i], "day")[,1])) names(tendias) <- names(tensionesx) ## na.STRUCTS para rellenar huecos (lo veremos más adelante) tendias.res <- na.omit (do.call (cbind, lapply (1:6, function(i) decompose (na.StructTS (ts(as.vector(tendias[,1]),freq=7))) $ random))) colnames(tendias.res) <- names(tendias) ccf (tendias.res[,"t.mat.dia"],tendias.res[,"pulso.mat"])
EJERCICIO
- Analiza el correlograma y la desviación típica de los residuos de AirPassengers pero con descomposición multiplicativa.
- Representa el correlograma del saldo anual en «cuenta.rda».
- Representa el correlograma semanal y mensual de «tensionesx».
- Representa el correlograma diario de las temperaturas de «zadeh».
- ¿Qué clase de objeto son los índices de la
xtsdedatosdetemperaturas_zadeh? - Representa el cruzcorrelograma de «zadeh».
2.5 Pronósticos.
- combinar
- estimación de tendencia
- modelos paramétricos
- modelos compartimentales en medicina
- modelo de Bas para ventas en economía
- etcétera
- regresión lineal, polinomial, exponencial…
- modelos paramétricos
- estimación de estacionalidad
- aditiva
- multiplicativa
- estructura del residuo
- estimación de tendencia
2.5.1 alisado exponencial
- ante todo, eliminar tendencia y estacionalidad
- la media puede cambiar, pero no hay información sobre el signo o magnitud del cambio
- ejemplo: ventas de un producto bien establecido en un mercado estable
- modelo \[\mu_t+w_t\]
- \(\mu_t\) media no estacionaria
- \(w_t\) desviaciones aleatorias independientes de media 0 y desviación típica \(\sigma\)
- estimación
\[a_t = \alpha\,x_t+(1-\alpha)\,a_{t-1}\]
- media móvil exponencialmente ponderada
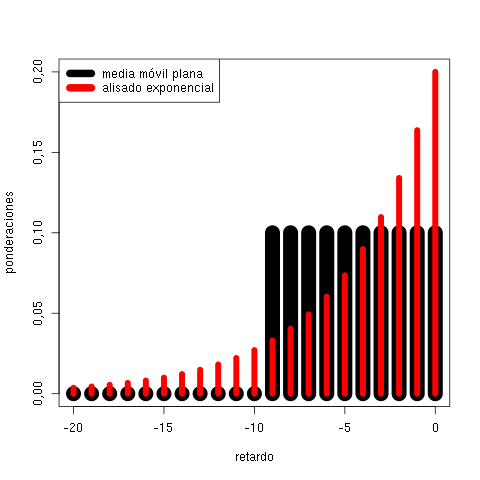
- \(\alpha\) es el parámetro de alisado (habitualmente 0,2)
- una estimación \(\hat\alpha\) puede obtenerse con R:
library (xts) pulso.mat <- to.period (tensionesx$pulso.mat, "week") [,2] plot (pulso.mat) ts.plot (pulso.mat) # permite añadir «lines» fácilmente lines (runmed(pulso.mat, 11), col=2, lwd=3) lines (filter(pulso.mat, rep(1/11,11)), col=3, lwd=3) lines (lowess(pulso.mat), col=4, lwd=3) # mismo alisado que «stl» lines (lowess(pulso.mat,f=1/3), col=5, lwd=3) plot (print (HoltWinters (pulso.mat, alpha=NULL, beta=FALSE, gamma=FALSE))) plot (print (HoltWinters (pulso.mat, alpha=0.1, beta=FALSE, gamma=FALSE)))
- método de Holt y Winters (aditivo; existe versión multiplicativa)
\[a_t = \alpha\,(x_t-s_{t-p})+(1-\alpha)\,(a_{t-1}+b_{t-1})\]
\[b_t = \beta\,(a_t-a_{t-1})+(1-\beta)\,b_{t-1}\]
\[s_t = \gamma\,(x_t-a_t) + (1-\gamma)\,s_{t-p}\]
donde
- \(p\) es el periodo
- \(a_t\) en el nivel (tendencia general)
- \(b_t\) es la pendiente (trend en la ayuda de R de «HoltWinters») o cambio del nivel
- \(s_t\) es el efecto estacional
- la esperanza de \(x_t\) sería \(a_t + s_t\)
- la predicción es \(\hat x_{n+k\mid n} = a_n + k\,b_n+s_{n+k-p}\) (\(k\leq p\))
HW <- function (serie, umbral, alpha=NULL, beta=NULL, gamma=NULL, seasonal="additive") { ajustados <- window (serie, end=umbral) hw <- HoltWinters (ajustados, alpha=alpha, beta=beta, gamma=gamma, seasonal=seasonal) pr <- predict (hw, floor((tsp(serie)[2]-umbral)*frequency(serie))) plot (serie) fi <- hw$fitted[,"xhat"] lines (as.vector(time(fi)), fi, col=3) lines (pr, col=2) } HW (AirPassengers, 1955, beta=FALSE, gamma=FALSE) HW (AirPassengers, 1955, gamma=FALSE) HW (AirPassengers, 1955, beta=FALSE) HW (AirPassengers, 1955) HW (AirPassengers, 1955, seasonal="multiplicative")
- media móvil exponencialmente ponderada
2.6 Modelos estocásticos básicos.
2.6.1 ruido blanco
- valores independientes
- valores con media 0
- valores con la misma distribución estadística
- si se trata de N\((0;\sigma)\) entonces es ruido blanco gausiano
plot (rnorm (100), type="l")
EJERCICIO
- representar histograma de ruido blanco
- representar correlograma de ruido blanco
2.6.2 paseo aleatorio
- \(x_t\) es paseo aleatorio si \[x_t=x_{t-1}+w_t=\sum_{s=1}^t w_s\]
w <- rnorm (1000) x <- cumsum (w) plot (x, type="l") acf (x) acf (diff (x))
EJERCICIO
- estudiar las correlaciones de diferencias de las series de ejemplo
2.6.3 modelo autorregresivo
- AR(p) = modelo autorregresivo de orden \(p\) \[x_t=\alpha_1\,x_{t-1}+\dots+\alpha_p\,x_{t-p}+w_t\] donde \(w_t\) es ruido blanco
- paseo aleatorio = AR(1) con \(\alpha_1=1\)
- alisado exponencial = AR(p) con \(\alpha_i=\alpha\,(1-\alpha)^i\)
- estimación mediante regresión sobre retardos
## AR(1) con coeficiente positivo x <- w <- rnorm (1000) for (t in 2:1000) x[t] <- 0.9 * x[t-1] + w[t] plot (x, type="l") acf (x) ## AR(1) con coeficiente negativo x <- w <- rnorm (1000) for (t in 2:1000) x[t] <- -0.9 * x[t-1] + w[t] plot (x, type="l") acf (x) ## AR(2) x <- w <- rnorm (1000) for (t in 3:1000) x[t] <- x[t-1] -0.6 * x[t-2] + w[t] plot (x, type="l") acf (x)
2.7 Análisis espectral.
- distribución de la variación de una serie temporal sobre la frecuencia
2.7.1 señal periódica
- \(t\) tiempo
- \(\omega\) frecuencia (velocidad en radianes por unidad de tiempo)
- \(f\) frecuencia (velocidad en Hz = hercios = ciclos por unidad de tiempo) \(\omega=2\pi\,f\)
- en R, frecuencia en ciclos por intervalo de muestreo
- \(\frac{2\pi}{\omega}\) periodo (tiempo por ciclo)
- \(A\) amplitud
- \(\psi\) fase
- onda senoidal \[A\,\mbox{sen}(\omega\,t+\psi) = A\,\mbox{cos}(\psi)\,\mbox{sen}(\omega\,t)+ A\,\mbox{sen}(\psi)\,\mbox{cos}(\omega\,t)\]
2.7.2 espectro
- sea \(n\) par y sea la serie \(x_t\) con \(t=1,\dots,n\)
- \(n\) longitud de registro
- intervalo de muestreo = tiempo entre \(t\) y \(t+1\)
- considerar la regresión de \(x_t\) frente a \(n-1\) variables regresoras
(serie de Fourier finita para una serie temporal discreta)
- \(\mbox{cos}\left(\frac{2\pi\,t}{n}\right)\) => coeficiente \(a_1\)
- \(\mbox{sen}\left(\frac{2\pi\,t}{n}\right)\) => coeficiente \(b_1\)
- \(\mbox{cos}\left(\frac{4\pi\,t}{n}\right)\) => coeficiente \(a_2\)
- \(\mbox{sen}\left(\frac{4\pi\,t}{n}\right)\) => coeficiente \(b_2\)
- \(\mbox{cos}\left(\frac{6\pi\,t}{n}\right)\) => coeficiente \(a_3\)
- \(\mbox{sen}\left(\frac{6\pi\,t}{n}\right)\) => coeficiente \(b_3\)
- …
- \(\mbox{cos}\left(\frac{2(n/2-1)\pi\,t}{n}\right)\) => coeficiente \(a_{n/2-1}\)
- \(\mbox{sen}\left(\frac{2(n/2-1)\pi\,t}{n}\right)\) => coeficiente \(b_{n/2-1}\)
- \(\mbox{cos}(\pi\,t)\) => coeficiente \(a_{n/2}\)
\[x_t = a_0+a_1\,\mbox{cos}\left(\frac{2\pi\,t}{n}\right)+\dots+a_{n/2}\,\mbox{cos}(\pi\,t)\]
- número de coeficientes = longitud de serie => ajuste exacto (suele calcularse con algoritmo
FFT)
- \(a_0=\bar x\)
- frecuencia más baja = 1 ciclo por longitud de registro = \(2\pi\) radianes por intervalo de muestreo
- frecuencia más alta = 0,5 ciclos por intervalo de muestreo => de \(-1\) a \(+1\) en cada intervalo
- armónico
- \(m\)-ésimo = senoidal que hace \(m\) ciclos en la longitud de registro
- primer armónico = frecuencia fundamental
- amplitud del armónico \(m\)-ésimo \[A_m=\sqrt{a_m^2+b_m^2}\]
- teorema de Parseval
\[\frac1n = \sum_{t=1}^n x_t^2=A_0^2 + \frac12\sum_{m=1}^{(n/2)-1} A_m^2+A_{n/2}^2\]
\[\mbox{Var}\,(x)=\frac12\sum_{m=1}^{(n/2)-1} A_m^2+A_{n/2}^2\]
- se basa en que los términos de senos y cosenos están incorrelados
- tabla de armónicos
armónico periodo frecuencia \(f\) frec. \(\omega\) contribución a la varianza 1 \(n\) \(1/n\) \(2\pi/n\) \(\frac12A_1^2\) 2 \(n/2\) \(2/n\) \(4\pi/n\) \(\frac12A_2^2\) 3 \(n/3\) \(3/n\) \(6\pi/n\) \(\frac12A_3^2\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(n/2-1\) \(n/(n/2-1)\) \((n/2-1)/n\) \((n-2)\pi/n\) \(\frac12A_{n/2-1}^2\) \(n/2\) 2 \(1/2\) \(\pi\) \(A_{n/2}^2\)
- periodograma crudo o espectro de Fourier
- diagrama de \(A_m^2\) frente a \(m\)
- en R:
spectrum (x) - intervalo de confianza asimétrico
- periodograma alisado o espectro muestral
- en R:
spectrum (x, span=k) - \(k\) en el número impar de muestras para la media móvil de Daniell
- ponderaciones de Daniell = (1/2; 1; 1; …; 1; 1; 1/2) : (k-1)
- mejor que ponderaciones constantes porque disminuye la influencia de la varianza de las frecuencias no-Fourier sobre el espectro de Fourier
- en R:
2.7.3 series simuladas
- ruido blanco
spectrum (x <- rnorm (1000), log = "no") spectrum (x, span = 101, log = "no")
- AR(1) con coeficiente positivo
- AR(1) con \(\alpha=0.9\)
layout (1:3) x <- w <- rnorm (1000) for (t in 2:1000) x[t] <- 0.9 * x[t-1] + w[t] plot (x, type="l") acf (x) spectrum (x, span=51, log="no")
- AR(1) con coeficiente negativo
- AR(1) con \(\alpha=-0.9\)
layout (1:3) x <- w <- rnorm (1000) for (t in 2:1000) x[t] <- -0.9 * x[t-1] + w[t] plot (x, type="l") acf (x) spectrum (x, span=51, log="no")
- AR(2)
- AR(2) con \(\alpha_1=1\) y \(\alpha_2=-0.6\)
layout (1:3) x <- w <- rnorm (1000) for (t in 3:1000) x[t] <- x[t-1] -0.6 * x[t-2] + w[t] plot (x, type="l") acf (x) spectrum (x, span=51, log="no")
2.7.4 series observadas
- tratamiento de datos capturados
- parámetros de la onda estimados por regresión no lineal
- uso de trasformada de Fourier
- cálculo de distorsión armónica total
## función para calcular armónicos, tasa de distorsión... estima <- function (x, # abscisas = tiempo y, # ordenadas = señal graf=TRUE, # si representar gráficos ## estimaciones iniciales de los parámetros: m0=mean(y), # altura del eje horizontal a0=diff(range(y))/2, # amplitud = (max-min):2 s=spectrum(y,plot=FALSE), # para calcular frecuencia ## omega = intervalo de muestreo omega0=s$freq[which.max(s$spec)]/diff(range(x))*length(x), psi0=0) { p <- nls (y ~ m + a * sin (2*pi * omega * x + psi), start = list(m=m0, a=a0, omega=omega0, psi=psi0)) if (graf) plot (x, y, type="l", xlab="microsegundos", ylab="") # original if (graf) lines (x, predict (p, data.frame(x=x)), col=2) # sinusoide ajustada periodo <- 1/coef(p)["omega"] psi <- coef(p)["psi"] desplaz <- (2*pi*(psi>0) - psi) / (2*pi) * periodo if (coef(p)["a"] < 0) desplaz <- desplaz + periodo/2 # si amplitud negativa i <- which (desplaz <= x & x < desplaz + periodo) # índices de ciclo entero Y <- fft (y[i]) ai <- seq (1, 7, 2) # armónicos na <- length(ai) a <- c (0, ai, length(Y) - ai) pa <- function (n) # predictora mediante armónicos Re (sum (Y[a+1] * exp (1i * 2*pi * a * n / length(Y)))) / length(Y) yt <- sapply (0:(length(x)-1) - sum(x<desplaz), pa) if (graf) lines (x, yt, type="l", col=3) # ajustada a partir de armónicos list (modelo = p, periodo = periodo, desplaz = desplaz, cc = Y[1], armonic = Y[ai+1], distors = sqrt (sum (Mod (Y[ai[-1]+1]) ** 2)) / Mod(Y[ai[1]+1]), ajustad = yt, ruido = y - yt) } ## función auxiliar d.t.trun <- function (x, ...) # para desviación típica truncada con «trim» sqrt (mean ((x - mean (x, ...)) ^ 2, ...)) ## función para presentar la información estimada informe <- function (x, y, ...) { e <- estima (x, y, ...) cat ("DISTORSIÓN =", e$distors, ".\n") ## límites para la detección de impulsos limites <- median (e$ruido) + 6 * c(-1,1) * d.t.trun (e$ruido, trim=0.05) cat ("IMPULSOS en los instantes:", x[e$ruido < limites[1] | e$ruido > limites[2]], ".\nFIN de IMPULSOS.\n") }
- ejemplo 1: ondas regulares (con eventuales impulsos)
d <- read.csv2("señales-eléctricas.csv") # cargamos datos x <- d[,1] # tiempo for (s in 2:5) { y <- d[,s] # señal (2, 3, 4, 5) cat (paste ("COLUMNA",s,"\n")) informe (x, y) }
- ejemplo 2
## - Valores entre 0 y 1023 (extremos de la escala de medida). ## - El valor 512 corresponde al valor nulo. ## - La corriente máxima a la que corresponde la señal es 0,7 A ## - La potencia aproximada es Imax/sqr(2).230. y <- scan("medicion corriente.csv") x <- 1:length(y) informe (x, y) ## intentamos de nuevo con una parte regular X <- x[1:500] Y <- y[1:500] informe (X, Y) ## estimación de la amplitud e <- estima(X,Y) amplitud <- diff(range(e$ajustad))/2 cat ("AMPLITUD = ", amplitud, "\n") ## buscamos zona con anomalía yt <- predict(e$modelo,data.frame(x=x)) diferencias <- abs (y - predict(e$modelo,data.frame(x=x))) anomalo.desde <- x [which (diferencias/amplitud > 0.3) [1]] plot(x,y,type="l"); lines(x,yt,col=3); abline(v=anomalo.desde,col=2)
2.8 Detección de cambios.
2.8.1 modelo
- sea la serie \[x_t = \theta(t)+\epsilon_t\]
- se puede sospechar que existe \(\tau\) tal que
- cambio de media: \[x_t=\theta_0(t)+\epsilon_t\qquad t=1,\dots,\tau-1\] \[x_t=\theta_1(t)+\epsilon_t\qquad t=\tau,\dots,T\phantom{-1}\] consideraremos el caso \(\theta_0\) y \(\theta_1\) y Var\((\epsilon_t)=\sigma^2\) constantes
- cambio de varianza \[\mbox{Var}(\epsilon_t)=\sigma_0^2\qquad t=1,\dots,\tau-1\] \[\mbox{Var}(\epsilon_t)=\sigma_1^2\qquad t=\tau,\dots,T\phantom{-1}\]
- \(\tau\) sería un punto de cambio
2.8.2 con valor de referencia y con muestra aleatoria simple (control de calidad básico)
- distribución estadística de la característica observada
- atributo dicótomo
- B(1;p)
- variable cuantitativa
- N(mu;sigma)
- desconocida con media mu y desviación sigma
- atributo dicótomo
- parámetro de interés
- p
- mu
- sigma
- muestra de control
- n = tamaño muestral
- ¿independencia entre observaciones?
- ¿representa la muestra la variabilidad esperada bajo control?
- nivel de significación
- H0: parámetro = valor de referencia
- H1: parámetro ≠ valor de referencia
- 3 sigma => nivel de significación bilateral 0,0027
2.8.3 sin valor de referencia
- paquete «changepoint» para detectar cambios
- en medias:
cpt.mean - en varianzas:
cpt.var - en ambas:
cpt.meanvar
- en medias:
- algoritmos
- un solo cambio
- AMOC (usado por omisión) Hinkley 1970
- varios
- PELT Killick 2012
- SegNeigh Auger 1989
- BinSeg Scott 1974
- un solo cambio
- penalizaciones
- verosimilitud penalizada
- revisión de Killick
- \( 2\,\log\,\max\,L - p\,\phi(n) \)
- \(p\) es el número de parámetros, incluidos los puntos de cambio
- \(n\) es el tamaño muestral
- "None"
- \(\phi(n) = 0\)
- contraste de razón de verosimilitudes
- el resto de métodos se usan fundamentalmente por poder ser generalizables a más de un punto de cambio
- "AIC"
- criterio de Akaike
- \(\phi(n) = 2\)
- asintóticamente sobrestima el número de parámetros
- "SCI"
- criterio de Schwarz
- \(\phi(n) = \log\,n\)
- "Hannan-Quinn"
- criterio de Hannan y Quinn
- \(\phi(n) = \log\,\log\,n\)
- "BIC", "MBIC"
- métodos bayesianos
- dependen de probabilidades a priori
- verosimilitud penalizada
library (changepoint) x <- c (rnorm(150,0,1), rnorm(50,0.5,1)) # tau = 151 ## alisado para apreciar cambios plot (x, type="l"); lines (runmed (x, 51), col=2, lwd=5) plot (x, type="l"); lines (filter (x, rep(1,51)/51), col=2, lwd=5) plot (x, type="l"); lines (lowess (time(x), x), col=2, lwd=5) library (changepoint) puntos <- cpt.mean (x) puntos # puede detectar 0 ó 1 plot (puntos) example (cpt.mean) # varios puntos de cambio de media example (cpt.var) # de varianza example (cpt.meanvar) # de media y varianza
EJERCICIO
- Comparar la efectividad de la penalización por omisión ("MBIC") con la de «penalty="None"» (u otras) en le ejemplo «x <- c (rnorm(150,0,1), rnorm(50,0.5,1))».
- Halla la potencia de detección de un cambio el función del salto de la media (\(\alpha\)): «x <- c (rnorm(150,0,1), rnorm(50,\(\alpha\),1))».
- Ídem pero suponiendo un modelo autoregresivo \(x_t = \mu_{0/1}+0.9\,x_{t-1}+w_t\).
- Prueba diferentes métodos para detectar cambios en los datos de ejemplo (tensiones, temperaturas…).