análisis de datos = análisis multivariante + aprendizaje automático
Índice
1. conceptos
1.1. datos
1.1.1. representación
- matriz/cuadro
- filas = instancias / individuos
- columnas = variables / características / atributos
- tipos de variables:
- numéricas / cuantitativas: continuas, discretas
- categóricas / cualitativas: nominales (dicótomas, polítomas), ordinales
1.1.2. preprocesamiento
- tipificación / normalización / estandarización
- imputación de valores faltantes
- codificación de variables categóricas
1.2. tipos de técnicas
- no supervisadas: sin variable respuesta
- supervisadas
- X = variables explicativas / independientes / exógenas / regresoras
- y = variable respuesta / dependiente / endógena
1.3. entrenamiento y validación
- conjunto de entrenamiento
- datos usados para ajustar los modelos
- conjunto de validación / test
- datos usados para evaluar rendimiento fuera de la muestra
1.3.1. cruz-validación / validación cruzada
- k-fold: dividir en k subconjuntos y rotar entrenamiento/test
- jackknife / Leave-One-Out (LOO)
- cada instancia como test
- entrenar con todas las demás
- variantes estratificadas (mantener proporción de clases)
1.4. evaluación de modelos supervisados
1.4.1. clasificación
- porcentaje de aciertos (accuracy)
- matriz de confusión
- verdaderos positivos, falsos positivos
- verdaderos negativos, falsos negativos
- métricas derivadas: sensibilidad (recall), especificidad; precision, F1-score
1.4.2. regresión
- error cuadrático medio (ECM, MSE), raíz del ECM (RMSE)
- error absoluto medio (MAE)
- devianza o log-loss para modelos probabilísticos
1.5. desequilibrio entre clases (class imbalance)
1.5.1. definición
- distribución no uniforme de las clases
- ejemplo: 95% de sanos, 5% de enfermos
1.5.2. consecuencias
- acccuracy engañosa
- modelos ingenues (naïf) con alto porcentaje de aciertos (clasificar todos como sanos)
1.5.3. estrategias de corrección
- ponderación de clases (class weighting)
- ajuste de la función de pérdida
- penalización diferencial de errores según la clase
- submuestreo (undersampling)
- reducción de la clase mayoritaria
- sobremuestreo (oversampling)
- replicación o generación sintética de instancias minoritarias
- ejemplo: SMOTE
- estrategias híbridas
- combinación de submuestreo y sobremuestreo
1.5.4. evaluación en presencia de desequilibrio
- métricas alternativas a accuracy
- sensibilidad, F1-score, balanced accuracy, AUC
1.6. conceptos adicionales
1.6.1. sesgo vs varianza
- infraajuste (underfitting) vs sobreajuste (overfitting)
1.6.2. modelo naïf / baseline
- estrategia simple para comparar (ej.: predecir la clase mayoritaria)
2. técnicas
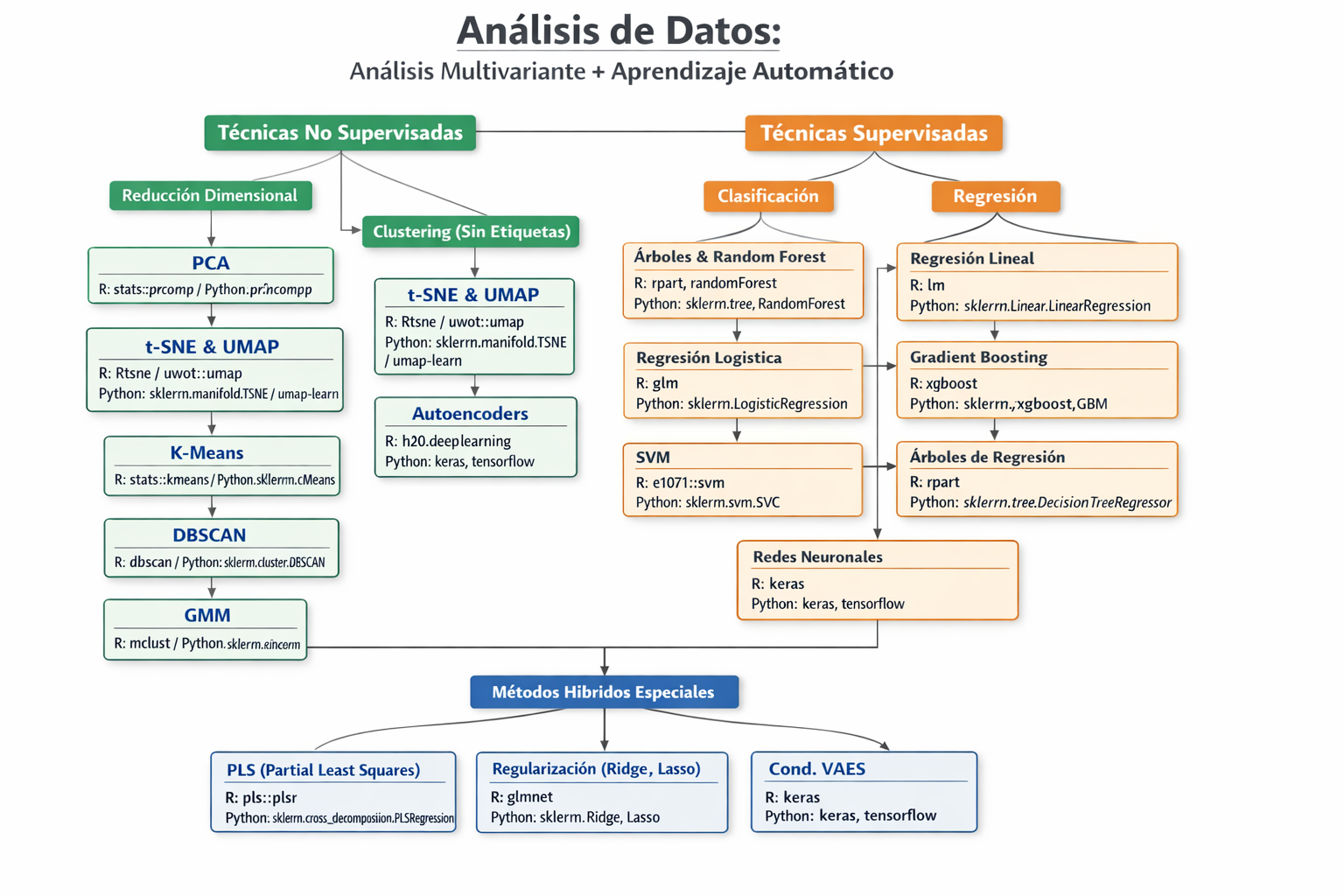
2.1. técnicas no supervisadas
2.1.1. reducción dimensional
- análisis de componentes principales (PCA)
- R: stats::prcomp / stats::princomp
- Python: sklearn.decomposition.PCA
- análisis de correspondencias (CA)
- R: FactoMineR::CA
- Python: prince.CA
- t-SNE
- R: Rtsne::Rtsne
- Python: sklearn.manifold.TSNE
- UMAP
- R: uwot::umap
- Python: umap-learn.UMAP
- Autoencoders (no supervisados)
- R: h2o::h2o.deeplearning
- Python: keras / tensorflow
2.1.2. clustering / clasificación sin etiquetas
- k-medias (k-means)
- R: stats::kmeans
- Python: sklearn.cluster.KMeans
- clustering jerárquico (hclust)
- R: stats::hclust
- Python: scipy.cluster.hierarchy.linkage / sklearn.cluster.AgglomerativeClustering
- DBSCAN
- R: dbscan::dbscan
- Python: sklearn.cluster.DBSCAN
- Mean Shift
- R: meanShiftR::meanShift
- Python: sklearn.cluster.MeanShift
- Gaussian Mixture Models (GMM)
- R: mclust::Mclust
- Python: sklearn.mixture.GaussianMixture
2.2. técnicas supervisadas
2.2.1. clasificación
- análisis discriminante lineal (LDA)
- R: MASS::lda
- Python: sklearn.discriminantanalysis.LinearDiscriminantAnalysis
- árboles de decisión
- R: rpart::rpart
- Python: sklearn.tree.DecisionTreeClassifier
- random forests
- R: randomForest::randomForest
- Python: sklearn.ensemble.RandomForestClassifier
- gradient boosting (XGBoost, LightGBM, CatBoost)
- R: xgboost::xgboost / lightgbm::lgb.train
- Python: xgboost.XGBClassifier / lightgbm.LGBMClassifier / catboost.CatBoostClassifier
- regresión logística
- R: stats::glm (family = binomial)
- Python: sklearn.linearmodel.LogisticRegression / statsmodels.api.Logit
- support vector machines (SVM)
- R: e1071::svm
- Python: sklearn.svm.SVC
- redes neuronales supervisadas
- R: keras::kerasmodelsequential / nnet::nnet
- Python: keras / tensorflow / torch.nn
2.2.2. regresión
- regresión lineal
- R: stats::lm
- Python: sklearn.linearmodel.LinearRegression / statsmodels.api.OLS
- regresión polinómica
- R: stats::lm (con polinomios en formula)
- Python: sklearn.preprocessing.PolynomialFeatures + LinearRegression
- árboles de regresión
- R: rpart::rpart
- Python: sklearn.tree.DecisionTreeRegressor
- random forests y gradient boosting para regresión
- R: randomForest::randomForest / xgboost::xgboost
- Python: sklearn.ensemble.RandomForestRegressor / xgboost.XGBRegressor
- redes neuronales supervisadas
- R: keras::kerasmodelsequential / nnet::nnet
- Python: keras / tensorflow / torch.nn
2.2.3. métodos híbridos / especiales
- Partial Least Squares (PLS) → reducción dimensional supervisada
- R: pls::plsr
- Python: sklearn.crossdecomposition.PLSRegression
- Regularización: Ridge, Lasso, Elastic Net
- R: glmnet::glmnet
- Python: sklearn.linearmodel.Ridge / Lasso / ElasticNet
- Modelos generativos supervisados (Conditional VAEs)
- R: keras::kerasmodelsequential
- Python: keras / tensorflow / torch