Análisis de datos 2
Índice
1. Optimización
1.1. generalidades
- Conceptos
- función objetivo
función para la que se quiere encontrar
- su valor óptimo = mejor = máximo o mínimo
- la solución óptima = combinación de argumentos tales que, si se les aplica la función objetivo, se obtiene su valor óptimo
téngase en cuenta:
- pueden existir múltiples soluciones óptimas
- hay problemas multiobjetivo = interesa obtener óptimos de varias funciones objetivo simultáneamente
otros nombre de la función objetivo:
- adaptación/ajuste (fitness) al maximizar en algoritmos genéticos
- pérdida al minimizar
- solución
- vector con valores para cada variable de la que dependa la función objetivo
- espacio de soluciones
- conjunto de todas las posibles soluciones
- restricción
- condición que ha de cumplir una solución para que se considere válida para calcular el óptimo
- solución factible
- solución que cumple las restricciones
- solución vecina
- solución que está cerca de otra dada, teniendo en cuenta una medida de distancia apropiada dentro del espacio de soluciones
- óptimo local
- solución cuyo valor de la función objetivo es mejor que el valor de la función objetivo en cualquiera de sus vecinos
- cambiando «es mejor» por «no es peor» se considerarían las soluciones con objetivos iguales a los de sus vecinos
- óptimo global
- solución cuyo valor de la función objetivo es mejor que el valor de la función objetivo en el resto del espacio de soluciones
- cambiando «es mejor» por «no es peor» se considerarían múltiples soluciones óptimas
- Muchos paquetes en R
1.2. determinística
1.2.1. irrestricta
1.2.1.1. unidimensional
En R: minimizar
objetivoen el intervalo entreizquierdayderechaoptimize (objetivo, c(izquierda, derecha))
- Ejercicio
- minimizar la función \[f(x) = \left\{\begin{array}{cl} e^\frac{-1}{\mid x-1\mid} & -1<x<4 \\ 10 & \text{otramente} \end{array} \right. \]
- maximizar \(f(x)=\text{sen}\, x\) con \(10<x<100\) grados sexagesimales
1.2.1.2. multidimensional
R
optim (..., method = "Nelder-Mead", ...) # robusto; por omisión optim (..., method = "BGFS", ...) # rápido
- GSL minimización multidimensional
Ejemplo: función de Rosenbroc
## ?optim fr <- function(x) { # Rosenbrock Banana function x1 <- x[1] x2 <- x[2] 100 * (x2 - x1 * x1)^2 + (1 - x1)^2 } ## "fr" está definida con un solo argumento, para usarla con "optim"
dibujar la función mediante
persp## definimos otra versión de "fr" pero con 2 argumentos ## para usarla con "outer": fr. <- Vectorize (function (x, y) fr (c (x, y))) x <- y <- seq(-5,5,.5); persp(x,y,outer(x,y,fr.),col=2,theta=0,phi=0) x <- y <- seq(-5,5,.5); persp(x,y,outer(x,y,fr.),col=2,theta=0,phi=-15) x <- y <- seq(-5,5,.5); persp(x,y,outer(x,y,fr.),col=2,theta=30,phi=30) x <- y <- seq(-5,5,.5); persp(x,y,outer(x,y,fr.),col=2,theta=90,phi=-30)
o bien mediante
rgl::surface3dinstall.packages("rgl") library(rgl) # permite girar la gráfica con el ratón x <- seq (-5, 5, .5); # si puede tu ordenador, prueba luego y <- seq (-5, 5, .5); # x<-seq(-3,3,.01);y<-seq(-2,5,.01); z <- outer (x, y, fr.) ## sigo el ejemplo de ?surface3d z <- z / max(abs(z)) * 10 # reescalamos; si no, queda en blanco ## se juntan dos paletas para apreciar mejor la parte baja nc <- 1000; abajo <- .02 # núm colores y %abajo; prueba 1e5 y 1e-4 arcoiris <- c (rainbow (nc*abajo), rainbow(nc-nc*abajo)) # ## (z-min(z))/(max(z)-min(z)) reescala entre 0 y 1 ## * (nc-1) + 1 da un índice entre 1 y nc, la longitud de la paleta colores <- arcoiris[(z-min(z))/(max(z)-min(z)) * (nc-1) + 1] clear3d() # coordenadas, etiquetas y tipo ("n" => nada) plot3d(x,y,z,"X","Y","Z","n") # para los ejes surface3d(x,y,z, color=colores, front="fill", back="lines")
aproximar el mínimo mediante
optimoptim (c(-5,-5), fr) optim (c(-5,-5), fr, method="Nelder-Mead") # por omisión, sin gradiente optim (c(-5,-5), fr, method="CG") # gradiente conjugado optim (c(-5,-5), fr, method="BFGS") # cuasiniuton (aproximación de la jesiana)
optimizarlo
print (optim (c(-5,-5), fr)) $ par -> inicio1 print (optim (inicio1, fr)) $ par -> inicio2 print (optim (inicio2, fr)) # óptimo
Ejercicio
- Sea \(X\) la variable «horas entre averías del aparato de aire acondicionado».
Sea la siguiente muestra aleatoria simple para \(X\)
x <- c (90, 10, 60, 186, 61, 49, 14, 24, 56, 20, 79, 84, 44, 59, 29, 118, 25, 156, 310, 76, 26, 44, 23, 62, 130, 208, 70, 101, 208)- Supóngase que \( X \hookrightarrow \gamma \,(\mu;\beta)\) con densidad \[ f_X(x)=\frac {\frac\beta\mu\,\left(\beta\,x\over\mu\right)^{\beta-1}\,e^{-\frac{\beta\,x}{\mu}}} {\Gamma(\beta)} \] donde \(\mu\) es la esperanza de \(X\) y \(\beta\) es el llamado parámetro de forma.
- Calcúlense estimaciones máximo-verosímiles de \(\mu\) y \(\beta\) dada la muesta
x.
Pasos
- Calcular la logverosimilitud \[ n\,\bigl[\log\beta-\log\mu-\log\Gamma(\beta)\bigr] + \sum_{i=1}^n\, (\beta-1)\,\log\frac{\beta\,x_i}{\mu} - \sum_{i=1}^n\,\frac{\beta\,x_i,}{\mu} \]
- Implementarla usando
functionpara generar una función de R- la función
lgammade R - una variable para almacenar el vector \(\left[\beta\,x_i /\mu\right]_{i=1}^n\) y así no calcularlo dos veces
- Maximizar la logverosimilitud. Como solución de partida se puede usar que
- la esperanza de \(X\) vale \(\mu\)
- la varianza de \(X\) vale \(\mu^2 / \beta\)
- según el método de los momentos, \(\hat\mu=\bar x\) y \(\hat \beta = (\hat\mu/\hat\sigma)^2 \)
logvero <- function (parametros) { mu <- parametros[1] beta <- parametros[2] n <- length(x) aux <- beta * x / mu n * (log(beta) - log(mu) - lgamma(beta)) + sum ((beta - 1) * log(aux)) - sum (aux) }
mean (x) # estimación de mu mean (x) ^ 2 / var (x) # estimación de beta ## representación múes <- seq (70, 100, 1) betas <- seq ( 1, 3, 0.1) ## usamos "Vectorize" porque "outer" requiere una función vectorizada fun <- Vectorize (function (mu, beta) logvero(c(mu,beta))) z <- outer (múes, betas, fun) persp (múes, betas, z, col=2, theta=40, phi=30) ## mediante "rgl" library (rgl) clear3d () plot3d (múes, betas, z, "mu", "beta", "logL", "n") surface3d (múes, betas, z) ## maximización optim (c (83.5, 1.4), logvero, control = list (fnscale = -1)) optim (c (83.5, 1.4), logvero, control = list (fnscale = -1), method="CG")
1.2.2. restringida
1.2.2.1. no lineal
- en caja (ortoedro paralelo a ejes)
El vector de cotas inferiores de las variables se da como argumento "lower" de "optim". Ídem con las cotas superiores y "upper":
optim (..., method = "L-BFGS-B", lower, upper ...)ejemplo artificial: buscar el mínimo de la función "flb" en la caja formada por intervalos desde 2 hasta 4 en cada dimensión:
## ejemplo obtenido en la ayuda ?optim flb <- function(x) { p <- length(x); sum(c(1, rep(4, p-1)) * (x - c(1, x[-p])^2)^2) }
representar gráficamente mediante
perspplot3d <- function (fun, xlim, ylim, n = 31, ...) ## fun = función de dos argumentos ## xlim = c(xmin,xmax) ylim = c(ymin,ymax) ## n = número de puntos en cada dimensión para la malla { x <- seq (xlim[1], xlim[2], length.out = n) y <- seq (ylim[1], ylim[2], length.out = n) z <- outer (x, y, fun) persp (x, y, z, ...) } ### k = 2 flb.env <- function (x,y) flb(c(x,y)) # envoltorio para plot3d plot3d (Vectorize(flb.env), c(2,4), c(2,4), theta=90, phi=-20) plot3d (Vectorize(flb.env), c(2,2.2), c(3.8,4), theta=90, phi=-20) # el mínimo parece estar con x=2, y=4 optim (c(3,3), flb, lower=c(2,2), upper=c(4,4), method="L-BFGS-B")
probar con
k <- 3### k = 3 mejor.x3 <- function (x1,x2) # dados x1 y x2, calcular x3 que minimiza flb optimize(function(x3) flb(c(x1,x2,x3)), c(2,4)) $ minimum flb.env1 <- function (x1,x2) flb(c(x1, x2, mejor.x3(x1,x2))) plot3d (Vectorize(flb.env1), c(2,4), c(2,4), theta=90, phi=-20, col=2) plot3d (Vectorize(flb.env1), c(2,2.1), c(2,2.4), theta=-40, phi=0, col=2) ## a ojo, x1 = x2 = 2 mejor.x2 <- function (x1,x3) optimize(function(x2) flb(c(x1,x2,x3)), c(2,4)) $ minimum flb.env2 <- function (x1,x3) flb(c(x1, mejor.x2(x1,x3), x3)) plot3d (Vectorize(flb.env2), c(2,4), c(2,4), theta=30, phi=-40, col=3) plot3d (Vectorize(flb.env2), c(2,2.2), c(3.8,4), theta=70, phi=0, col=3) ## a ojo, x1 = 2, x3 = 4 mejor.x1 <- function (x2,x3) optimize(function(x1) flb(c(x1,x2,x3)), c(2,4)) $ minimum flb.env3 <- function (x2,x3) flb(c(mejor.x1(x2,x3), x2, x3)) plot3d (Vectorize(flb.env3), c(2,4), c(2,4), theta=30, phi=-40, col=4) plot3d (Vectorize(flb.env3), c(2,2.2), c(3.8,4), theta=120, phi=-10, col=4) ## a ojo, x2 = 2, x3 = 4 optim (c(3,3,3), flb, lower=c(2,2,2), upper=c(4,4,4), method="L-BFGS-B") ## mínimo en 2.000000 2.109093 4.000000
ejemplo práctico
- datos de PISA 2012 en España
- datos de los tres cebos para estimar exageración: ST62Q04, ST62Q11, ST62Q13
- https://oecd.org/pisa/data
- buscar: pisa database 2012 - codebook for student…
- respuestas de 0 a 4
- modelo matemático para ajustar la respuesta del alumno \(i\) al ítem \(j\)
\[ R_{ij} \approx 4 \cdot C_i \cdot D_j \]
donde
- \(0\leq C_i\leq 1\) es la tendencia a la exageración del alumno \(i\)
- \(0\leq D_j\leq 1\) es la verosimilez del cebo \(j\), lo real que parece
- estimar exageración y verosimilez mediante mínimos cuadrados \[ \sum_{i,j}(R_{ij} - 4 \cdot \hat C_i \cdot \hat D_j)^2 \]
- datos
- fichero RDA con respuestas a cebos de PISA 2012 en España
- comenzar con pocos datos (10, 100…) porque la convergencia con los datos completos puede tardar horas
OC <- read.table (paste0 ("http://bellman.ciencias.uniovi.es/~carleos/", "master/manadine/curso2/AnalisisDatos2/apuntes/", "analisisdatos2/datos/pisa/overclaim.txt")) ene <- 1000 OC0 <- OC[1:ene,] nj <- ncol(OC) system.time (print (optim (rep (0.5, ene+nj), function (cd) { c <- cd [1 : ene] d <- cd [(ene+1) : (ene+nj)] sum ((OC0 - 4 * c %o% d) ^ 2) }, lower = 0, upper = 1, method = "L-BFGS-B")))
- alternativa usando media por alumno: \[ \bar R_{i} \approx 4 \cdot C_i \cdot \bar D \] \[ \hat C_i = \frac {\bar R_{i}} {4 \cdot \bar D} \] puede hacerse que la minimización dependa sólo de los \(D_j\)
d1 <- mean (OC0[["ST62Q04n"]], na.rm=TRUE) d2 <- mean (OC0[["ST62Q11n"]], na.rm=TRUE) d3 <- mean (OC0[["ST62Q13n"]], na.rm=TRUE) dx <- max (d1, d2, d3) optim (c (d1, d2, d3) / dx * 0.9, function (d) { c <- apply (OC0, 1, mean) / 4 / mean(d) c <- pmax (0, pmin (1, c)) sum ((OC0 - 4 * c %o% d) ^ 2) }, method = "L-BFGS-B", lower = 0, upper = 1)
- restricciones lineales
Optimizar una función sujeta a restricciones de desigualdades lineales. \[ \min f(\vec\theta) \mbox{ sujeta a } U\cdot\vec\theta\geq\vec c \] o sea \[ \min f(\theta_1,...,\theta_n) \mbox{ sujeta a } \sum_{j=1}^n\,u_{ij}\cdot \theta_j \geq c_i\quad \forall\,i=1,...,m \] En R básico existe la función
constrOptim(theta, f, grad, ui, ci)
- Si el tercer argumento (
grad) esNULL, se usa el algoritmoNelder-Mead. Si no, hay que proporcionar una función gradiente. Las restricciones
ui %*% theta - ci >= 0
definen la región factible.
Para maximizar, úsese la opción
control = list(fnscale = -1)
- La solución inicial
thetadebe pertenecer a la región factible.
## función banana de Rosenbroc fr <- function(x) { x1 <- x[1] x2 <- x[2] 100 * (x2 - x1 * x1)^2 + (1 - x1)^2 } ## usando "optim" como en la sección anterior optim (c(3,3), fr, lower = c(2,2), upper = c(4,4), method="L-BFGS-B") ## la versión equivalente con "constrOptim" constrOptim (c(3,3), fr, NULL, ui = cbind (c(1,-1, 0,0), c(0,0, 1,-1)), ci = c(2,-4, 2,-4))
Ejemplo con restricciones lineales arbitrarias (no de caja) \[ \min b_1^2 + b_2^2 + b_3^2 - 10 b_2\qquad\mbox{sujeta a}\qquad\begin{array}{rrrcr} -4b_1 & -3b_2 & & \geq & -8 \\ 2b_1 & +b_2 & & \geq & 2 \\ & -2b_2 & b_3 & \geq & 0\end{array} \]
f <- function(b) sum(b^2) - 10*b[2] U <- matrix (c(-4,2,0, -3,1,-2, 0,0,1), 3) c <- c(-8,2,0) constrOptim(c(2,-1,-1), f, NULL, U, c)
Por tanto, se pueden resolver problemas de programación lineal o cuadrática, pero hace falta una solución factible como valor inicial.
- Si el tercer argumento (
1.2.2.2. lineal
\[ \max\quad 0.6x_1+0.5x_2\qquad\mbox{sujeta a}\qquad\begin{array}{rrcr} x_1 & +2x_2 & \leq &1\\ 3x_1 & +x_2 & \leq &2\end{array} \]
- LP solve
desde R
install.packages("lpSolve") library("lpSolve") m <- lp ("max", # o "min" c(0.6, 0.5), rbind(c(1,2),c(3,1)), "<=", # "=" = "=="; "<" = "<="; ">" = ">=" c(1,2))
- ejercicio: Disponemos de 600 g de fármaco con el que se pueden
elaborar pastillas grandes o pequeñas. Cada pastilla grande
requiere 40 g de fármaco y se cobra a 2 €. Cada pequeña, 30 g y 1
€. Se necesitan al menos tres pastillas grandes y, como mínimo,
el doble de pequeñas que de grandes. ¿Cuántas pastillas se han de
elaborar de cada clase para que el beneficio sea máximo? (fuente)
- planteamiento
- Variables:
- \(x\) el número de pastillas grandes
- \(y\) el número de pastillas pequeñas
- Objetivo:
- \(\max 2x + y\)
- Restricciones:
- \(40x + 30y \leq 600\)
- \(x \geq 3\)
- \(y \geq 2x\)
- \(x \geq 0\)
- \(y \geq 0\)
- Variables:
solución mediante LpSolve en R
- la dirección es
max - consideraremos a las variables en el orden
x,y - el vector de coeficientes del objetivo es
c(2,1) la matriz de coeficientes de las restricciones es
40 30 1 0 -2 1 # porque y > 2x => -2x+y > 0
las restricciones \(x,y\geq0\) se consideran por omisión
- el vector lado derecho, el de términos independientes, vale
c(600,3,0)(el0por la inecuación \(-2x+y\geq0\))
library(lpSolve) resultado <- lp("max", c(2, 1), matrix(c(40,1,-2, 30,0,1), 3), # ojo a cómo queda la matriz final c("<", ">", ">"), # <600, >3, >2x c(600, 3, 0)) resultado$solution
- la dirección es
- planteamiento
-
var x1; var x2; maximize obj: 0.6 * x1 + 0.5 * x2; s.t. c1: x1 + 2 * x2 <= 1; s.t. c2: 3 * x1 + x2 <= 2; solve; display x1, x2; end;
1.3. heurísticas
1.3.1. Intro y ejemplo
1.3.1.1. metaheurística
- heurística: algoritmo ad hoc… (quizá sin base teórica)
- meta: …generalizable
problemas complejos (combinatorios)
n=5 n=10 n=100 n=1000 n 5 10 100 1.000 n^2 25 100 10.000 1.000.000 n^3 125 1.000 1.000.000 1.000.000.000 2^n 32 1.024 1,27 · 10^30 1,07 · 10^301 n! 120 3.628.800 9,33 · 10^157 4,02 · 102.567 - probabilísticos
1.3.1.2. n reinas
- https://es.wikipedia.org/wiki/Problema_de_las_ocho_reinas
compilar el C++ y ejecutarlo
g++ nreinas.cpp ./a.out
redirigir la salida a un fichero
./a.out > salida.txt ./a.out | tee salida.txt
medir cuánto tiempo tarda en ejecutarse
time ./a.out
conseguir que pare tras hallar una solución
time ./a.out | head -n 2
- cambiar el número de reinas; ¿hasta cuántas reinas es posible resolver en un tiempo razonable?
- hacer gráfica de tiempos en función de número de reinas (ejemplo)
traducir el algoritmo a R y ejecutarlo midiendo tiempo
reinas <- function (k, col, diag45, diag135, nReinas=8) { if (k==nReinas) stop (paste (col, collapse="-")) else for (j in 1:nReinas) if (!(j%in%col) && !((j-k)%in%diag45) && !((j+k)%in%diag135)) { reinas (k+1, c (col, j), c (diag45, j-k), c (diag135, j+k), nReinas) } } reinas (0, integer(0), integer(0), integer(0))
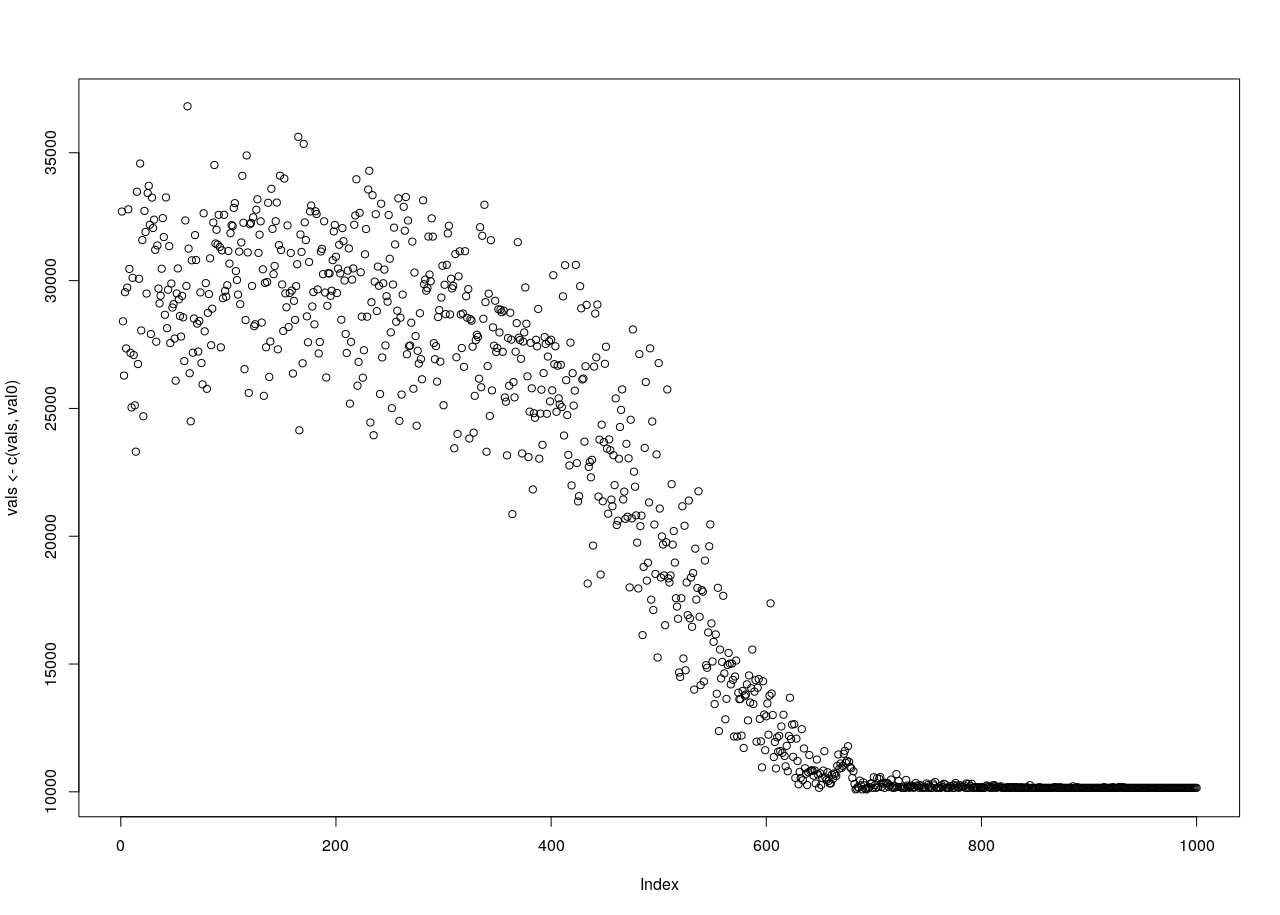
1.3.2. Recocido
- ejemplos
- video (de aquí)
- gif (de aquí)
example (optim) # en R; ejemplo de función «salvaje»- implementación en R
- algoritmo
- implementación
- simplificar el programa de ejemplo eliminando la parte gráfica (solución) e interpretar el algoritmo
- adaptar el algoritmo para resolver el problema de las reinas;
- necesitamos:
- elegir una codificación del problema; por ejemplo, permutaciones;
- una función para calcular el número de colisiones, dada una permutación;
- una función para generar una permutación vecina, dada una permutación;
- en R
- en R mediante "optim"
- necesitamos:
- calcular tiempos y comparar con versión determinística;
- paralelizar el programa
- ejercicios previos:
comparar tiempos
Sys.sleep (10) system.time (Sys.sleep (10)) pausa <- function () Sys.sleep(10) system.time (pausa ()) system.time ({pausa (); pausa ()}) system.time (replicate (2, pausa())) pausa <- function (x) Sys.sleep(10) system.time (lapply (1:2, pausa)) system.time (parallel::mclapply (1:2, pausa))
en algunos sistemas operativos
mclapplyno funciona (no ejecuta en paralelo sino secuencialmente); en tales casos hay que emplear un procedimiento más latoso basado en las funcionesmakeCluster,parLapplyystopCluster; véanse este listado y el ejercicio 11 (el último) de este examenrecordar
lapply- mtcars
- Crear una lista que contenga, el R2 y los coeficientes de la regresión de la variable MPG de MTCARS frente a la variable WT.
- Crear una lista que contenga, para cada variable de MTCARS, el R2 y los coeficientes de la regresión de la variable MPG frente a la susodicha.
- Crear una lista que contenga, para cada variable de MTCARS, el R2 y la matriz con los coeficientes y sus errores típicos, t-valores y p-valores.
- recocido
- definir una función
recocidoque ejecute un recocido y devuelva información de interés para el problema - usar
lapplypara guardar en una lista los resultados de varios recocidos - definir una función que combine los dos pasos anteriores
- entrada: número de recocidos que ejecutar
- salida: la lista creada por
lapply
- definir una función
- mtcars
- cargar la biblioteca (distribuida con R básico):
library(parallel) - detectar número de hilos/procesos en paralelo posibles:
detectCores() - probar
mclapply- ejemplo trivial
generar un millón de muestras de tamaño cien de una población gausiana y calcular la media muestral en cada una; guardar sólo la desviación típica de dichas medias muestrales
dtmediamuestral <- function (i) sd (replicate (1e6, mean (rnorm (100, 170, 15)))) # la "i" se descarta; es para el "mclapply"
realizar dicha operación en paralelo para varios hilos y comparar tiempos de ejecución
system.time (mclapply (1:4, dtmediamuestral))
si los tiempos no concuerdan con lo esperado, recoger la basura antes de la medición
gc (); system.time (mclapply (1:4, dtmediamuestral))
- ejemplo trivial
- probar
mcparallel- en este caso,
mclapplyviene mal porque espera a que se acaben todos los hilos - ejemplo de uso con las reinas
- en este caso,
- ejercicios previos:
- ejercicio: aplicar recocido para ruta más corta entre ciudades de "eurodist"
- listado
- salida
- gráfico
- determinístico
example(optim) # en R; último ejemplo
{kind=link}
{kind=link}
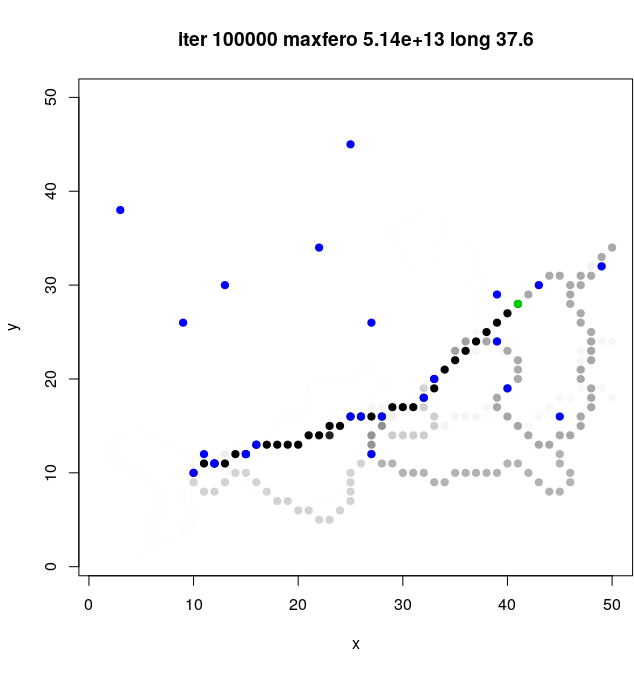
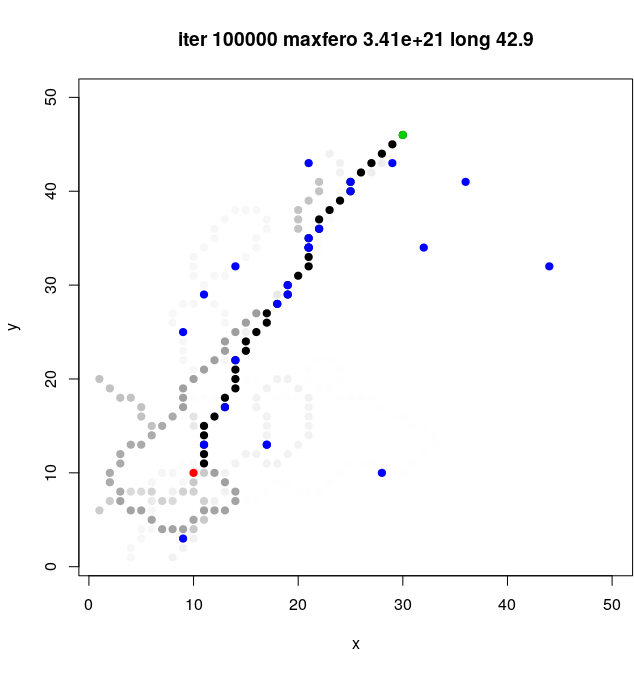
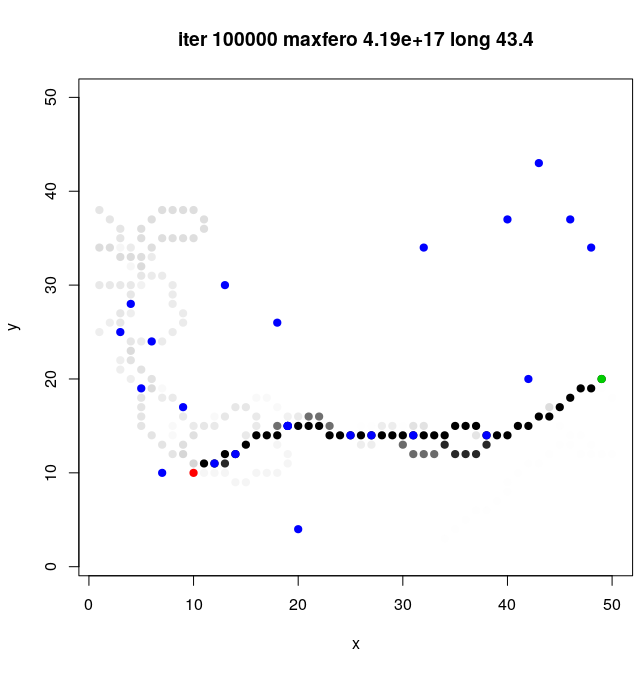
1.3.3. Enjambre
- algoritmo
- implementar
- adaptar para reinas (ejemplo)
- ¿paralelizar?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1.3.5. Genéticos
- intro - evolución y selección
- esquema (wikipedia)
- n reinas
- implementar:
- población de 100 individuos
- torneo con 5 candidatos
- cruzar los 2 mejores para crear 2 vástagos
- realizar 1 mutación en cada vástago (con probabilidad pMut en cada uno)
- seleccionar los 100 mejores de los 102 individuos resultantes
- hasta ahora
- probar una biblioteca de R (genalg, GA…)
- mejorar la evaluación (p.ej. este artículo)
- implementar:
- hibridación
1.3.6. Lenguajes compilados
- fortran desde R
1.3.7. Ejercicios
1.3.7.1. Selección de reproductores
En producción animal es necesario controlar la consanguinidad de los futuros reproductores. Esta matriz indica la relación de parentesco entre parejas de 215 individuos de una generación.
- Se pretende seleccionar 1 lote de 90 individuos de forma que la media de las relaciones en el lote sea lo menor posible.
- Se pretende seleccionar 1 lote de 90 individuos de forma que, en primer lugar, la mediana de las relaciones en el lote sea lo menor posible y, en segundo lugar, la varianza de las relaciones en los lotes sea lo menor posible.
- Se pretende seleccionar 3 lotes de 30 individuos cada uno, de forma que, en primer lugar, el máximo de las relaciones en los lotes sea lo menor posible y, en segundo lugar, que la media de las relaciones en los lotes sea lo menor posible.
Resuelve cada situación.
1.3.7.2. Selección de marcadores
- Datos en este directorio
- mapa: cromosoma y posición
- genotipos:
- ID del individuo
- alelos (a,A)
- 0 = homocigoto (aa)
- 1 = heterocigoto (aA)
- 2 = homocigoto (AA)
- 5 = desconocido
- Objetivo
- Escoger 50.000 marcadores
- Maximizar distancia entre ellos (suma de distancias cuadráticas)
- Maximizar heterocigosis esperada
1.3.8. Programación genética
2. Macrodatos
2.1. formatos textuales
Los formatos textuales tienen la ventaja de que pueden ser examinados directamente por un humano, sin necesidad de un programa específico (le bastaría un programa genérico como un editor de texto).
2.1.1. tabulares
2.1.1.1. campos separados por un delimitador único (dsv)
- registro = renglón
- campos separados por coma (csv), punto-y-coma (csv2), tabulador (tsv), tubo "|" (psv)
- habitualmente llamados CSV todos ellos
read.csv read.csv2 read.delim read.delim2
- ejercicio 1
- cargar estos datos
- comprobar si alguna variable influye en "proportion"
- ejercicio 2
- cargar estos datos
- crea una variable "nombre.completo" que contenga sólo mayúsculas
- crea una variable "NombreCompleto" que esté en minúsculas, salvo las iniciales
- ejercicio 3
- cargar estos datos
- hacer análisis de componentes principales sobre "ce", "altp", "anchp"
- hallar influencia de "cul" y "edadm" en "ce", "altp" y "anchp"
- ejercicio 4
- cargar estos datos
- crear variable "familia.de.curso" con los tres primeros caracteres de "CodEspecialidad"
- hacer una tabla de frecuencias de familias por cada mes
- hacer análisis de correspondencias con esa tabla
- ejercicio 5
- cargar estos datos
- calcular la variable "edad" actual
- crear una tabla con "id", "edad", "sexo", "sit.laboral.ultima", "numero.de.registros"
- crear una tabla con "id", "edad", "sexo", "sit.laboral.ultima", "numero.de.registros", "tiempo.trabajando" (trabaja si situación=1)
- relacionar las tres últimas variables con "edad" y "sexo"
- ejercicio 6
- cargar estos datos
- el segundo campo es el identificador (ID)
- los campos que contienen ACGT son genotipos
- hallar las frecuencias de ACGT en total
solución 1 (Bash)
cat genotipos | recode cl..data | cut -d' ' -f7- | tr ' ' '\n' | sort | uniq -c
solución 2 (cut + R)
resultados <- sapply (seq (7, 1160007, 10000), function (primeracolumna) { system (paste0 ("cut -d' ' -f ", primeracolumna, "-", primeracolumna+9999, " genotipos > genotipos.tmp")) table (c (as.matrix (read.table ("genotipos.tmp")))) }) resultados <- c (resultados, list ({system ("cut -d' ' -f1170007-1178858 genotipos > genotipos.tmp"); table (c (as.matrix (read.table ("genotipos.tmp"))))})) ### queda combinar los resultados ## opción 1 n0 <- nA <- nC <- nG <- nT <- nTRUE <- 0 for (i in 1:118) { ## n0 <- n0 + ifelse (is.na (resultados[[i]]["0"]), 0, resultados[[i]]["0"]) ## n0 <- n0 + if (is.na (resultados[[i]]["0"])) 0 else resultados[[i]]["0"] ## if (!is.na (resultados[[i]]["0"])) n0 <- n0 + resultados[[i]]["0"] n0 <- sum (n0, resultados[[i]]["0"], na.rm=TRUE) nA <- sum (n0, resultados[[i]]["A"], na.rm=TRUE) nC <- sum (n0, resultados[[i]]["C"], na.rm=TRUE) nG <- sum (n0, resultados[[i]]["G"], na.rm=TRUE) nT <- sum (n0, resultados[[i]]["T"], na.rm=TRUE) nTRUE <- sum (n0, resultados[[i]]["TRUE"], na.rm=TRUE) } ## opción 2 apply (do.call (rbind, lapply (resultados, function (x) x[c("0","A","C","G","T","TRUE")])), 2, sum, na.rm=TRUE)
- hallar las frecuencias de ACGT para cada ID y comprobar si existen tendencias respecto al número ID
opción «casi todo R»
numero.de.renglones <- as.numeric (strsplit (system ("wc -l genotipos", intern=TRUE), " ") [[1]] [1]) resultados <- lapply (1 : numero.de.renglones, function (i) { recuentos <- system (paste0 ("head -n", i, " genotipos | tail -n 1 | ", "recode cl..data | cut -d' ' -f7- | tr ' ' '\n' | sort | uniq -c"), intern = TRUE) recuentos <- strsplit (recuentos, " +") # crea p.ej.: "" "287" "T" resultado <- as.numeric (sapply (recuentos, function (x) x[2])) names (resultado) <- sapply (recuentos, function (x) x[3]) resultado }) resultados <- as.data.frame (do.call (rbind, resultados)) resultados$id <- as.numeric (system ("cut -d' ' -f2 genotipos", intern=TRUE))
opción «casi todo Bash»
for i in {1..23}; do head -n$i genotipos | tail -n1 | awk '{ORS=" id ";print $2}'; head -n$i genotipos | tail -n1 | recode cl..data | cut -d' ' -f7- | tr ' ' '\n' | sort | uniq -c | tr '\n' ' '; echo; done > tabla.txt
2.1.1.2. campos separados por espacio
read.table
- ejercicio 1
- cargar estos datos
- relacionar
pesoy edad al destete
- ejercicio 2
- cargar estos datos
- relacionar
pesoy día de la semana de nacimiento
2.1.1.3. ancho fijo
read.fwf
- ejercicio 1
- INE.es -> productos y servicios -> información estadística -> ficheros de microdatos
- demografía y población -> encuesta nacional de inmigrantes
- cargar TODOS los datos en R
- hacer gráfica de HAESP (habla español) usando etiquetas apropiadas
- hacer gráfica de idiomas hablados (IDIO1 a IDIO6) usando etiquetas apropiadas
- pista 1
- pista 2
- pista 3
- pista 4
- pista 5
- extra: automatizarlo
- pista 6
- ejercicio 2
- INE.es -> productos y servicios -> información estadística -> ficheros de microdatos -> demografía y población
- censos de población -> ( [diseño de registro] y [fichero de macrodatos] )
- hallar las cinco provincias con mayor (y las cinco con menor) número medio de hijos por familia y las cinco con mayor (y menor) porcentaje de familias numerosas
2.1.2. ramificados árboles grafos
2.1.2.1. sex sexp s-expresiones
- p-lista
El nombre viene de «lista de propiedades».
(nombre Fulano edad 44 aficiones (leer cantar viajar) peso 88)
Equivaldría a la expresión de R:
list (nombre="Fulano", edad=44, aficiones=c("leer","cantar","viajar"), peso=88) - a-lista
El nombre viene de «lista de asociaciones». Su uso es similar al de las p-listas.
((nombre Fulano) (edad 44) (aficiones leer cantar viajar) (peso 88))
Con pretty-print:
((nombre Fulano) (edad 44) (aficiones leer cantar viajar) (peso 88)) - pueden expresar programas
La siguiente expresión en R:
(sqrt(30*pi) - 1) / (3 + 8 * log(a/b) / (1 + 2 + 3 + 4 + 5 + 6))
se expresaría así, por ejemplo:
(/ (- (sqrt (* 30 pi))) (/ (+ 3 8 (log (/ a b))) (+ 1 2 3 4 5 6)))Las siguientes instrucciones de control en R:
for (i in 0:9) if (i %% 2) print (paste (i, "es impar")) else print (paste (i, "es par"))se expresarían así, por ejemplo:
(dotimes (i 10) (if (oddp i) (print (list i 'es 'impar)) (print (list i 'es 'par))))En R se puede obtener el árbol asociado a un programa, pero es más complejo:
e <- expression ( (2+3)/sqrt(5) ) as.list(e[[1]]) as.list(e[[1]][[2]]) as.list(e[[1]][[2]][[2]])
Nótese que el operador paréntesis introduce un nivel adicional. Otro ejemplo con instrucción de control:
e <- expression (for (i in 1:10) print (i**2)) as.list (e[[1]]) as.list (e[[1]][[3]]) as.list (e[[1]][[4]][[2]])
2.1.2.2. xml
ejemplo de árbol
<individuo> <nombre>Fulano</nombre> <edad>44</edad> <aficiones> <aficion>leer</aficion> <aficion>cantar</aficion> <aficion>viajar</aficion> </aficiones> <peso>88</peso> </individuo>
en R
library (XML) xmlParse("individuo.xml") -> x xmlToList (x) -> l- minería de internet (web scraping)
- en R
- paquete
rvest - ejemplo: obtención de las tablas sobre PIB por cabeza de wikipedia
- paquete
- con navegadores textuales (lynx, links, elinks, w3m, eww…)
permiten obtener texto plano a partir de una página ueb, p.ej.
w3m -dump -cols 300 'https://es.wikipedia.org/wiki/Anexo:Pa%C3%ADses_por_PIB_(nominal)_per_c%C3%A1pita' > pagina.txt less -S pagina.txtese texto puede tratarse luego con un editor para crear un fichero legible mediante
read.fwfen R- no soportan javascript (excepto browsh o edbrowse)
- con navegadores para ciegos
- edbrowse
- navegación fácilmente automatizable
- en R
- ejercicio 1
- Cargar empleo-situacion.xml.
- Calcular el tiempo que ha trabajado cada individuo (como en el ejercicio5 de aquí)
- solución
- ejercicio 2
- Cargar playas.xml (fichero obtenido de http://transparencia.gijon.es/set/medio-ambiente/CalidadAgua, http://transparencia.gijon.es/set/medio-ambiente/CalidadAgua)
- Informar de la calidad del agua.
- ejercicio 3
Importar como lista de R la página Titulares del dUO (
htmlParseyxmlToList)- HTML
<html> <head><title>dUO</title></head> <body> <h1>Diario de la U.O.</h1> <h2>Actos</h2> <ul> <li>Concurso <a href="http://bellman.ciencias.uniovi.es/incubadora">Incubadora</a>. <li>Conferencia. </ul> <h2>Avisos</h2> <ul> <li>Comienza el <strong>MANADINE</strong>. <li>Pérdida de título. </ul> </body> </html>
- Navegar la lista e intentar obtener la lista de novedades (de actos, por ejemplo)
- Intentar lo mismo accediendo al enlace RSS
2.1.2.3. json
- ejemplo de árbol
{
nombre: "Fulano",
edad: 44,
aficiones: ["leer", "cantar", "viajar"],
peso: 88
}
En R:
### https://docs.mongodb.com/manual/tutorial/query-documents/ ## db.inventory.insertMany([ ## { item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" }, ## { item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" }, ## { item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" }, ## { item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" }, ## { item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" } ## ]); d <- list ( list (item = "journal", qty = 25, size = list (s = 320, uom = "cc"), status = "A" ), list (item = "notebook", qty = 50, size = list (h = 8.5, w = 11, uom = "in"), status = "A" ), list (item = "paper", qty = 100, size = list (h = 8.5, w = 11, uom = "in"), status = "D" ), list (item = "planner", qty = 75, size = list (h = 22.85, w = 30, uom = "cm"), status = "D" ), list (item = "postcard", qty = 45, size = list (h = 10, w = 15.25, uom = "cm"), status = "A" ) ) library (jsonlite) j <- toJSON (d) # trasformar a JSON j <- toJSON (d, pretty = TRUE) # idem humanolegible cat (j, file="/tmp/ejemplo.json") # guardar en fichero dj <- fromJSON (j) # trasformar de JSON a dataframe dim (dj) # ojo: dataframes anidados y con listas dj$size # dataframe dentro de dj DJ <- flatten (dj) # intenta trasformar a dataframe normal dim (DJ) DJ[[1]] # lista en vez de vector ## hace falta trasformar los NULL en NA para obtener un dataframe normal D <- data.frame (lapply (DJ, function (v) unlist (ifelse (sapply(v,is.null), NA, v)))) ## uso lapply en vez de sapply para que no genere una matriz (que son homogéneas en tipo de datos)
2.2. formatos binarios
Los formatos binarios permiten acceder a la documentación almacenada en el disco duro de una manera mucho más rápida que los formatos textuales. Por tanto, son convenientes para almacenar datos que no caben en la memoria del ordenador.
2.2.1. tabulares SQL
Un banco de datos relacional (siglas en inglés: RDBM) contiene una o varias tablas (rectangulares, como dataframes). Dos tablas pueden estar relacionadas a través de un campo clave.
+----------+ +---------------+ +--------------------+
| cursos | | perfil | | municipios |
+----------+ +---------------+ +--------------------+
| título | +--* identificador | +--* nombreDelMunicipio |
| IDalumno *--+ | edad | | | partidoJudicial |
| sector | | sexo | | +--------------------+
+----------+ | municipio *--+
+---------------+
Con esas relaciones podríamos obtener la relación entre sector profesional al que se asocian los cursos y el partido judicial al que pertenece el alumno.
2.2.1.1. gestores populares de BB.DD.
- PostgreSQL
- página ueb
- características técnicas avanzadas
- muy bien programada
- fiable y tolerante a fallos
- extensible
- portable
- MySQL MariaDB
- SQLite
- página ueb
- muy sencilla y cómoda (no requiere crear usuarios)
- extendidísima (incluida en Android, Firefox…)
apt install r-cran-rsqlite
2.2.1.2. lenguaje SQL
- comparado con R
R postgresql (listar databases) \l ls() ; DBI::dbListTables() \d sapply(tabla,class) SELECT * from tabla WHERE FALSE; \gdesc R sql tabla <- read.csv("/tmp/fichero.csv") CREATE TABLE tabla (col1 integer, col2 varchar(100), col3 bigint); COPY tabla FROM '/tmp/fichero.csv' WITH NULL AS '' CSV HEADER; write.csv(tabla[1:5,], "/tmp/fichero.csv") \copy (SELECT * FROM tabla LIMIT 5) TO '/tmp/fichero.csv' WITH NULL AS 'NA' CSV HEADER;rm(tabla) DROP TABLE tabla; names(tabla) SELECT * from tabla WHERE FALSE; nrows(tabla) SELECT COUNT(*) FROM tabla; (rápido pero aproximado) EXPLAIN SELECT * FROM tabla; tabla$columna SELECT columna FROM tabla; tabla[c("col1","col2")] SELECT col1,col2 FROM tabla; subset(tabla,,c(col1,col2)) tabla SELECT * FROM tabla; tabla[1:n,] SELECT * FROM tabla LIMIT n; tabla[tabla$columna==valor,] SELECT * FROM tabla WHERE columna = valor; tabla[which(tabla$columna==valor),] select(tabla, columna==valor) == = != <> o bien != < > <= >= < > <= >= is.na(columna) ; !is.na(columna) columna IS NULL ; columna IS NOT NULL barra vertical OR & AND ! NOT %in% c(…,…) IN (…,…) columna >= alfa & columna <= alfa BETWEEN alfa AND beta grep ("UNIOVI$", columna) columna LIKE '%UNIOVI' grep ("^UNI", columna) columna LIKE 'UNI%' grep ("UNI", columna) columna LIKE '%UNI%' grep("^UO.*ES", columna) columna LIKE 'UO%ES' tabla[order(tabla$columna),] SELECT * FROM tabla ORDER BY columna; tabla[order(tabla$col1,tabla$col2),] SELECT * FROM tabla ORDER BY col1,col2; tabla[order(tabla$col1,tabla$col2),decreasing=TRUE] SELECT * FROM tabla ORDER BY columna DESC; cbind(tabla$col1,tabla$col2/tabla$col3) SELECT col1,col2/col3 FROM tabla; with(tabla, cbind(col1,col2/col3)) mean(tabla$columna,na.rm=TRUE) SELECT AVG(columna) FROM tabla; sum(!is.na(tabla$columna),na.rm=TRUE) SELECT COUNT(columna) FROM tabla; min(tabla$columna,na.rm=TRUE) SELECT MIN(columna) FROM tabla; max(tabla$columna,na.rm=TRUE) SELECT MAX(columna) FROM tabla; sum(tabla$columna,na.rm=TRUE) SELECT SUM(columna) FROM tabla; unique(tabla$columna) SELECT DISTINCT columna FROM tabla; length(unique(tabla$columna)) SELECT COUNT(DISTINCT(columna)) FROM tabla; by(tabla$col1, tabla$col2, mean) SELECT col1,AVG(col2) FROM tabla GROUP BY col1; by(tabla$col1, tabla$col2, mean) SELECT col1,AVG(col2) FROM tabla GROUP BY 1; Filter (function(x)x>50, by(tabla$col1, tabla$col2, mean) SELECT col1,AVG(col2) FROM tabla GROUP BY 1 HAVING AVG(col2)>50; with(tabla, cbind(nombre,precio,oferta=ifelse(precio<10,"sí","no"))) SELECT nombre,precio,CASE WHEN precio<10 THEN 'sí' ELSE 'no' END AS oferta FROM tabla tabla1 [tabla1$col1 %in% tabla2$col1 , ] SELECT * FROM tabla1 WHERE col1 IN (SELECT col1 FROM tabla2); merge(tabla1, tabla2, by.x="id", by.y="codigo") SELECT * FROM tabla1,tabla2 WHERE tabla1.id = tabla2.codigo; merge(tabla1, tabla2, by.x="id", by.y="codigo") SELECT * FROM tabla1 INNER JOIN tabla2 ON tabla1.id = tabla2.codigo; merge(tabla1, tabla2, by.x="id", by.y="codigo", all.x=TRUE) SELECT * FROM tabla1 LEFT JOIN tabla2 ON tabla1.id = tabla2.codigo; merge(tabla1, tabla2, by.x="id", by.y="codigo", all.y=TRUE) SELECT * FROM tabla1 RIGHT JOIN tabla2 ON tabla1.id = tabla2.codigo; merge(tabla1, tabla2, by.x="id", by.y="codigo", all=TRUE) SELECT * FROM tabla1 FULL JOIN tabla2 ON tabla1.id = tabla2.codigo; - crear tablas
create table tablavacas (id integer, peso double, nombre text); insert into tablavacas (123290,295,'ESTRELLA');
- mysql
Lo habitual es importar desde fuera:
mysqlimport -u usuario -p --delete --local --fields-terminated-by=';' test vacas.csv
- postgresql
\c ejemplos create table empleo_contratos (NumCorrelativo integer, tipoContrato integer, fechaInicio bigint, fechaFin bigint, ocupacion integer, ActEconomica integer); create table empleo_cursos (Numcorrelativo integer, FechaInicio varchar(15), CodEspecialidad varchar(15), DenominacionEspecialidad varchar(200)); create table empleo_perfil (NumCorrelativo integer, NivelFormativo integer, SitLaboralUltima varchar(10), FechaSitLaboralUltima bigint, FechaNacimiento bigint, Sexo integer, Municipio integer, SitLaboralHistórico varchar(10), FechaInicioSitLaboralHistórico bigint); copy empleo_contratos from '/tmp/empleo_contratos.csv' with csv header null as ' '; copy empleo_cursos from '/tmp/empleo_cursos.csv' with csv header null as ' '; copy empleo_perfil from '/tmp/empleo_perfil.csv' with csv header null as '';
- sqlite
EJERCICIO
con los datos de empleabilidad de aquí, crear tres tablas mediante SQLite3
bash> sqlite3 sqlite> .open empleo.db sqlite> .mode csv sqlite> .import empleo_cursos.csv cursos sqlite> .import empleo_contratos.csv contratos sqlite> .import empleo_perfil.csv perfil sqlite> .tables sqlite> .schema perfil sqlite> .quit
- mysql
- consultas
select * from tablavacas; select id,peso/edad from tablavacas; select id,peso/edad as crecimiento from tablavacas; select * where peso > 10 and edad < 500; select id,peso/edad as crecimiento from tablavacas having crecimiento > 1;
Comparando cadenas:
%representa cero o algún carácter_representa exactamente un carácter cualquiera
Agregación:
select avg(peso) as pesomedio from tablavacas group by genotipo;
Otros agregadores:
count(),min(),max(),var_samp(),stddev_samp()Por ejemplo:select genotipo,count(*) from tablavacas group by genotipo; select sexo,genotipo,count(*) from tablavacas group by sexo,genotipo; select sexo,count(*),avg(peso) as media,stddev_samp(peso) as dt from tablavacas group by genotipo;
EJERCICIO
bash> sqlite3 sqlite> .open empleo.db sqlite> .tables sqlite> .schema perfil sqlite> select count(*) from perfil; sqlite> select * from perfil limit 20; sqlite> select * from perfil limit 20 offset 100; sqlite> select * from perfil where NumCorrelativo=2; sqlite> select perfil.*,cursos.*,contratos.* from perfil,cursos,contratos where perfil.NumCorrelativo=contratos.NumCorrelativo and perfil.NumCorrelativo=cursos.Numcorrelativo limit 5; sqlite> .headers on sqlite> .mode csv sqlite> .output empleo_todo.csv sqlite> select perfil.*,cursos.*,contratos.* from perfil,cursos,contratos where perfil.NumCorrelativo=contratos.NumCorrelativo and perfil.NumCorrelativo=cursos.Numcorrelativo; sqlite> .output stdout
primeros campos:
select * from pragma_table_info('pisa') limit 5; select cnt,count(*) from pisa group by CNT; - varias tablas
Juntar varias tablas, teniendo una columna
idvacade enlace:select facilidadparto from partos join tablavacas using(idvaca);
Se usa LEFT JOIN para mantener los registros de la primera tabla, aunque no haya correspondencia con la segunda. EJERCICIO
bash> sqlite3 empleo.db sqlite> select count(*) from perfil,cursos; 29787628 sqlite> select count(*) from perfil,cursos where perfil.NumCorrelativo=cursos.Numcorrelativo; 2510 sqlite> select count(*) from perfil join cursos where perfil.NumCorrelativo=cursos.Numcorrelativo; 2510 sqlite> select count(*) from perfil left join cursos on perfil.NumCorrelativo=cursos.Numcorrelativo; 43350
- modificar
update tablavacas set peso=198,alzada=150 where id=123123; delete from tablavacas where id=123123; drop table tablavacas drop database aseava;
2.2.2. ramificados NoSQL
2.2.2.1. MongoDB
- características
- BSON: JSON binarizado
- cualquier contenido (p.ej. vídeos)
- optimizada; sólo disponible para arquitecturas i386 y amd64
- ejemplo
Instalación en Debian, Ubuntu, etcétera:
sudo apt install mongodb
Importaremos los datos de R
mtcars, suponiendo que han sido exportados a un fichero de texto CSV:mongoimport --file mtcars.csv --type csv --headerline
En versiones antiguas, hay que añadir una opción
--collection, por ejemplo:mongoimport --file mtcars.csv --type csv --headerline --collection mtcars
Si
mtcarsestuviera en formato JSON, usado por omisión por MongoDB:mongoimport --file mtcars.json
Las consultas pueden hacerse directamente desde el cliente de MongoDB:
mongo > show collections > db.mtcars.find({am: 0}).count()EJERCICIO
- Importar en MongoDB los datos de empleo (ojo a la opción «–jsonArray» de «mongodb»).
- Hallar cuántos varones y mujeres hay.